Віртуалізатор оточуючого звуку з динамічним стисненням діапазону й спосіб







Формула / Реферат
1. Спосіб віртуалізації оточуючого звуку для одержання вихідних сигналів з метою їхнього відтворення парою фізичних акустичних систем, що перебувають у певних фізичних положеннях стосовно слухача, де жодне з фізичних положень не є положенням з ряду положень тилових джерел, де зазначений спосіб включає наступні етапи на яких:
(a) у відповідь на вхідні звукові сигнали, що є ознаками звуку з положень тилових джерел, генерують оточуючі сигнали, придатні для приведення акустичних систем у певних фізичних положеннях у стан випускання звуку, сприйманого слухачем як звук, що випускається із зазначених положень тилових джерел, що полягає у стисненні динамічного діапазону на вхідних звукових сигналах, та
(b) генерують вихідні сигнали у відповідь на оточуючі сигнали й щонайменше ще один вхідний звуковий сигнал, де кожний зазначений ще один вхідний звуковий сигнал є ознакою звуку з відповідного положення переднього джерела, так, щоб вихідні сигнали були придатні для приведення акустичних систем у певних фізичних положеннях у стан випускання звуку, що слухач сприймає як звук, що випускається з положень тилових джерел і з кожного зазначеного положення переднього джерела.
2. Спосіб за п. 1, який відрізняється тим, що стиснення динамічного діапазону виконують шляхом нелінійного підсилення вхідних звукових сигналів.
3. Спосіб за будь-яким з пп. 1-2, який відрізняється тим, що етап (а) включає етап виконання стиснення динамічного діапазону, що включає підсилення кожного із вхідних звукових сигналів, що має рівень, що не перевищує заздалегідь задане порогове значення, нелінійно залежно від величини, на яку цей рівень менше порогового значення.
4. Спосіб за п. 3, який відрізняється тим, що рівень являє собою середній, за тимчасовим вікном, рівень зазначеного кожного із вхідних звукових сигналів.
5. Спосіб за будь-яким з пп. 1-4, який відрізняється тим, що фізичні акустичні системи являють собою передні гучномовці, які перебувають у певних фізичних положеннях перед слухачем, і етап (а) включає етап генерування лівого та правого оточуючих сигналів у відповідь на лівий та правий тилові вхідні сигнали.
6. Спосіб за п. 5, який відрізняється тим, що етап (b) включає етап генерування вихідних сигналів у відповідь на оточуючі сигнали й у відповідь на лівий вхідний звуковий сигнал, що є ознакою звуку з положення лівого переднього джерела, правий вхідний звуковий сигнал, що є ознакою звуку з положення правого переднього джерела і центрального вхідного звукового сигналу, що є ознакою звуку з положення центрального переднього джерела.
7. Спосіб за п. 6, який відрізняється тим, що етап (b) включає етап генерування фантомного центрального каналу у відповідь на центральний вхідний звуковий сигнал.
8. Спосіб за будь-яким з пп. 1-7, який відрізняється тим, що етап (а) включає етап генерування оточуючих сигналів, що включає перетворення вхідних звукових сигналів відповідно до функції моделювання сприйняття звуку.
9. Спосіб за п. 8, який відрізняється тим, що вхідні звукові сигнали являють собою лівий тиловий вхідний сигнал, що є ознакою звуку з лівого тилового джерела, і правий тиловий вхідний сигнал, що є ознакою звуку із правого тилового джерела, і етап (а) включає наступні етапи, на яких:
перетворюють лівий тиловий вхідний сигнал відповідно до функції моделювання сприйняття звуку для генерування першого віртуалізованого звукового сигналу, що є ознакою звуку з лівого тилового джерела, як такого, що попадає в ліве вухо слухача, і другого віртуалізованого звукового сигналу, що є ознакою звуку з лівого тилового джерела, як такого, що попадає в праве вухо слухача, та
перетворюють правий тиловий вхідний сигнал відповідно до функції моделювання сприйняття звуку для генерування третього віртуалізованого звукового сигналу, що є ознакою звуку із правого тилового джерела, як такого, що попадає в ліве вухо слухача, і четвертого віртуалізованого звукового сигналу, що є ознакою звуку із правого тилового джерела, як такого, що попадає в праве вухо слухача.
10. Спосіб за будь-яким з пп. 1-9, який відрізняється тим, що етап (а) включає етап генерування оточуючих сигналів, що включає виконання декореляції на вхідних звукових сигналах.
11. Спосіб за будь-яким з пп. 1-10, який відрізняється тим, що етап (а) включає етап генерування оточуючих сигналів, що включає виконання заглушення перехресних перешкод на вхідних звукових сигналах.
12. Спосіб за п. 1, який відрізняється тим, що фізичні гучномовці являють собою навушники, і етап (а) виконують без виконання заглушення перехресних перешкод на вхідних звукових сигналах.
13. Спосіб за п. 1, який відрізняється тим, що етап (а) включає наступні етапи, на яких:
виконують стиснення динамічного діапазону на вхідних звукових сигналах з метою генерування стиснених звукових сигналів,
виконують декореляцію на стиснених звукових сигналах з метою генерування декорельованих звукових сигналів,
перетворюють декорельовані звукові сигнали відповідно до функції моделювання сприйняття звуку з метою генерування віртуалізованих звукових сигналів, та
виконують заглушення перехресних перешкод на віртуалізованих звукових сигналах з метою генерування оточуючих сигналів.
14. Система віртуалізації оточуючого звуку, що сконфігурована для одержання вихідних сигналів з метою їхнього відтворення парою фізичних акустичних систем, що перебувають у певних фізичних положеннях стосовно слухача, яка відрізняється тим, що жодне з фізичних положень не є положенням з ряду положень тилових джерел, що містить:
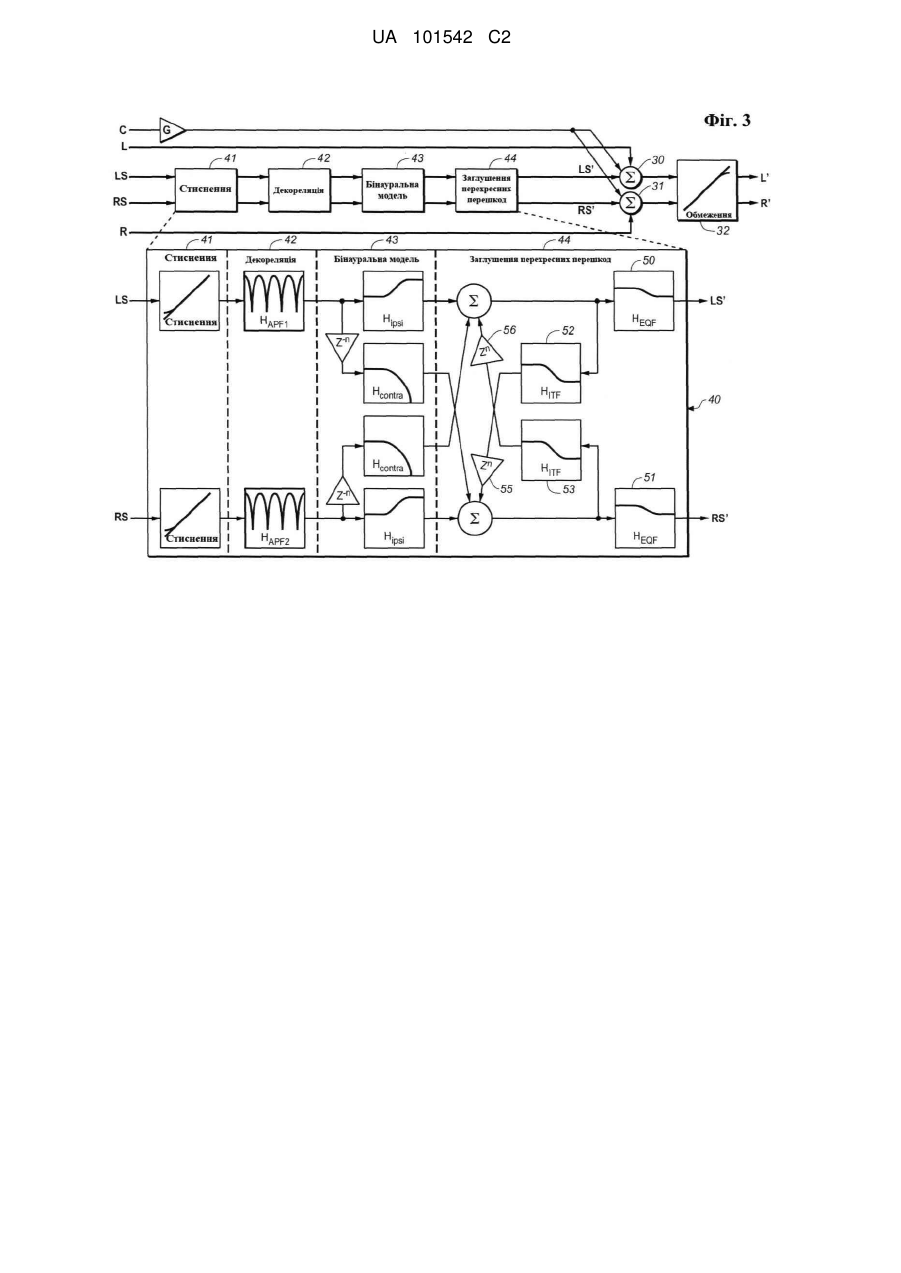
підсистему (40) віртуалізатора оточуючого звуку, підключену й сконфігуровану для генерування оточуючих сигналів у відповідь на вхідні звукові сигнали, що полягає у виконанні стиснення динамічного діапазону на вхідних звукових сигналах, де вхідні звукові сигнали є ознаками звуку з положень тилових джерел, а оточуючі сигнали придатні для приведення акустичних систем у певних фізичних положеннях у стан випускання звуку, що слухач сприймає як звук, що випускається із зазначених положень тилових джерел, та
другу підсистему (30, 31), підключену й сконфігуровану для генерування вихідних сигналів у відповідь на оточуючі сигнали й щонайменше ще одного вхідного звукового сигналу, де кожний зазначений ще один вхідний звуковий сигнал є ознакою звуку з відповідного положення переднього джерела, так, щоб вихідні сигнали були придатні для приведення акустичних систем, що перебувають у певних фізичних положеннях, у стан випускання звуку, що слухач сприймає як звук, що випускається з положень тилових джерел і з кожного зазначеного положення переднього джерела.
15. Система за п. 14, яка відрізняється тим, що підсистема (40) віртуалізатора оточуючого звуку сконфігурована для виконання стиснення динамічного діапазону шляхом нелінійного підсилення вхідних звукових сигналів.
Текст
Реферат: Спосіб і система генерування вихідних сигналів, призначених для відтворення двома фізичними акустичними системами у відповідь на вхідні звукові сигнали, що є ознаками звуку з ряду положень джерел, що включають щонайменше два тилових положення. Як правило, вхідні сигнали є ознаками звуку із трьох передніх положень і двох тилових положень (лівого та правого оточуючих джерел). Віртуалізатор генерує лівий та правий оточуючі вихідні сигнали, придатні для приведення передніх гучномовців у стан випускання звуку, що слухач сприймає як звук, що випускається з тилових джерел. Як правило, віртуалізатор генерує лівий та правий вихідні сигнали шляхом перетворення вхідних сигналів тилових джерел відповідно до функції моделювання сприйняття звуку. Для забезпечення гарної чутності зазначених віртуальних каналів у присутності інших каналів, віртуалізатор виконує стиснення динамічного діапазону на вхідних сигналах тилових джерел. Стиснення динамічного діапазону, переважно, здійснюється шляхом підсилення вхідних сигналів тилових джерел або їх частково оброблених версій, нелінійно щодо вхідних сигналів передніх джерел. UA 101542 C2 (12) UA 101542 C2 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 Перехресне посилання на споріднену заявку Дана заявка заявляє пріоритет попередньої заявки на патент США №61/122647, поданої 15 грудня 2008 p., яка посиланням повністю включається в даний опис. Область техніки винаходу Винахід відноситься до систем віртуалізаціії оточуючого звуку й способам генерування вихідних сигналів, призначених для відтворення парою фізичних акустичних систем (навушників або гучномовців), розташованих у певних вихідних положеннях, у відповідь на, щонайменше, два вхідних звукових сигнали, що є ознаками звуку з декількох положень джерел, включаючи, щонайменше, два тилових положення. Як правило, вихідні сигнали генеруються у відповідь на набір з п'яти вхідних сигналів, що є ознаками звуку із трьох передніх положень (лівого, центрального й правого передніх положень) і двох тилових положень (лівого оточуючого і правого оточуючого тилових джерел). Передумови винаходу У всьому цьому розкритті, включаючи формулу винаходу, термін "віртуалізатор" (або "система віртуалізатора") означає систему, що підключена й сконфігурована для прийому N вхідних звукових сигналів (що є ознаками звуку з ряду положень джерел) і генерування Μ вихідних звукових сигналів, які призначені для відтворення поруч із Μ фізичних акустичних систем (наприклад, навушниками або гучномовцями), розташованими у вихідних положеннях, які відрізняються від положень джерел, де N і Μ - числа, кожне з яких більше одиниці. N може дорівнювати Μ або відрізнятися від М. Віртуалізатор генерує (або намагається генерувати) вихідні звукові сигнали так, щоб при їхньому відтворенні слухач сприймав відтворені сигнали як сигнали, що випускаються з положень джерел, які відрізняються від вихідних положень фізичних акустичних систем (джерела й вихідні положення розташовуються відносно слухача). Наприклад, у випадку, коли Μ = 2, а N > 3, віртуалізатор виконує понижувальне мікшування N вихідних сигналів для стереофонічного відтворення. В іншому прикладі, де Ν = Μ = 2, вхідні сигнали є ознаками звуку із двох тилових положень джерел (за головою слухача), і віртуалізатор генерує два вихідних звукових сигнали для відтворення стереофонічними гучномовцями, розташованими перед слухачем, так, щоб слухач сприймав відтворені сигнали як сигнали, що випускаються від положень джерел (за головою слухача), а не від положень гучномовців (перед головою слухача). У всьому даному описі, включаючи формулу винаходу, вираз "тилове" положення (наприклад, "тилове положення джерела") означає положення за головою слухача, а вираз "переднє" положення (наприклад, "переднє положення джерела") означає положення перед головою слухача. Подібним чином, вираз "передні" динаміки означає динаміки, розташовані перед головою слухача, а "задні динаміки" - означає динаміки, розташовані за головою слухача. У всьому даному описі, включаючи формулу винаходу, вираз "система" використовується в широкому сенсі для позначення пристрою, системи або підсистеми. Наприклад, підсистема, що реалізує віртуалізатор, може бути названа "системою віртуалізатора", а система, що включає цю підсистему (наприклад, система, що генерує Μ вихідних сигналів у відповідь на X + Υ вхідних сигналів, у якій підсистема генерує X вхідних сигналів, а інші Υ вхідних сигналів приймаються від зовнішнього джерела), також може бути названа системою віртуалізатора. У всьому даному описі, включаючи формулу винаходу, вираз "відтворення" сигналів динаміками означає створення умов для виведення звуку акустичними системами у відповідь на сигнали, включаючи будь-яке необхідне підсилення та/або іншу обробку сигналів. Віртуальний оточуючий звук може сприяти створенню сприйняття того, що присутня більша кількість джерел звуку, ніж є в наявності фізичних акустичних систем (наприклад, навушників або гучномовців). Як правило, нормальному слухачеві для того, щоб відчувати відтворений звук так, нібито він випускається безліччю джерел звуку, необхідно, щонайменше, дві акустичні системи. Наприклад, розглянемо простий віртуалізатор оточуючого звуку, підключений і сконфігурований для прийому вхідних звукових сигналів від трьох джерел (лівого, центрального й правого) і для генерування вихідних звукових сигналів для двох фізичних гучномовців (симетрично розташованих перед слухачем) у відповідь на вхідні звукові сигнали. Такий віртуалізатор направляє вхідний сигнал від лівого джерела до лівої акустичної системи, направляє вхідний сигнал від правого джерела до правої акустичної системи й розділяє вхідний сигнал від центрального джерела нарівно між лівою й правою акустичними системами. Вихідний сигнал віртуалізатора, що є ознакою вхідного сигналу від центрального джерела, звичайно називається "фантомним" центральним каналом. Слухач сприймає відтворений вихідний звуковий сигнал так, нібито він включає центральний канал, що випускається центральною 1 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 акустичною системою, що перебуває між лівою та правою акустичними системами, а лівий і правий канали - як такі, що випускаються лівою та правою акустичними системами. Інший традиційний віртуалізатор оточуючого звуку (показаний на фіг. 1) відомий як "LoRo", або віртуалізатор з понижувальним мікшуванням тільки лівого та тільки правого передніх каналів. Віртуалізатор підключається для прийому п'яти вхідних звукових сигналів: лівого ("L"), центрального ("С") і правого ("R") передніх каналів, і лівого оточуючого ("LS") і правого оточуючого ("RS") тилових каналів. Віртуалізатор за фіг. 1 комбінує вхідні сигнали зазначеним чином для відтворення через лівий та правий фізичні гучномовці (які повинні розташовуватися перед слухачем): вхідний центральний сигнал С підсилюється в підсилювачі G, і підсилений вихідний сигнал підсилювача G складається із вхідними сигналами L і LS, утворюючи лівий вихідний сигнал ("Lo"), спрямовуваний до лівої акустичної системи, і складається із вхідними сигналами R і RS, утворюючи правий вихідний сигнал ("Ro"), спрямовуваний до правої акустичної системи. Інший традиційний віртуалізатор оточуючого звуку показаний на фіг. 2. Цей віртуалізатор підключається для прийому п'яти вхідних звукових сигналів (лівого ("L"), центрального ("С") та правого ("R") передніх каналів, що є ознаками передніх джерел L, С і R, а також лівого оточуючого ("LS") та правого оточуючого ("RS") тилових каналів, що є ознаками тилових джерел LS і RS) і конфігурується для генерування фантомного центрального каналу шляхом поділу вхідного сигналу від центрального каналу С нарівно між лівим та правим сигналами для приведення в дію пари фізичних передніх гучномовців (розташованих перед слухачем). Віртуалізатор за фіг. 2 також конфігурується з метою використання підсистеми 10 віртуалізатора для того, щоб генерувати лівий та правий вихідні сигнали LS' і RS', придатні для приведення передніх гучномовців у стан випускання звуку, що слухач сприймає як звук, відтворений тиловий (оточуючий) звук, що випускається джерелами RS і LS за слухачем. Точніше, підсистема 10 віртуалізатора конфігурується для генерування вихідних звукових сигналів LS' і RS' у відповідь на вхідні сигнали тилових каналів (LS і RS), що полягає у перетворенні вхідних сигналів відповідно до функції моделювання сприйняття звуку (HRTF). Реалізуючи належну HRTF, підсистема 10 віртуалізації може генерувати пари вихідних сигналів, які можуть відтворюватися двома фізичними гучномовцями, розташованими перед слухачем так, щоб слухач сприймав вихідні сигнали гучномовців як сигнали, що випускаються парою джерел, розташованих у кожному з великої кількості можливих положень (наприклад, положень за головою слухача). Віртуалізатор за фіг. 2 також підсилює вхідний центральний сигнал С у підсилювачі G, і підсилений вихідний сигнал підсилювача G складається із вхідним сигналом L і вихідним сигналом LS' підсистеми 10, утворюючи лівий вихідний сигнал (" L' "), призначений для направлення до лівого гучномовця, і складається із вхідним сигналом R і вихідним сигналом RS' підсистеми 10, утворюючи правий вихідний сигнал (" R' "), призначений для направлення до правого гучномовця. Для генерування звукових сигналів, які при відтворенні парою фізичних акустичних систем, розташованих перед слухачем, сприймаються барабанними перетинками слухача як звук з гучномовців, що перебувають у кожному з великої кількості можливих положень (включаючи положення за слухачем), системи віртуального оточуючого звуку традиційно використовують функції моделювання сприйняття звуку (HRTF). Недоліком традиційно використовуваної однієї стандартної HRTF (або ряду стандартних HRTF) при генеруванні звукових сигналів, придатних для використання багатьма слухачами (наприклад, широкою публікою) є те, що точна HRTF для кожного конкретного слухача повинна залежати від характерних рис слухового апарата слухача. Тому функції HRTF повинні широко варіюватися для різних слухачів, і одинична HRTF, загалом, не буде придатною для всіх або багатьох слухачів. Якщо для подання вихідних сигналів віртуалізатора використовуються (на відміну від навушників) два гучномовці, необхідно прикласти зусилля для ізоляції звуку від лівого гучномовця до лівого вуха, і від правого гучномовця - до правого вуха. Традиційно для досягнення такої ізоляції використовується пристрій заглушення перехресних перешкод. Для реалізації заглушення перехресних перешкод віртуалізатори традиційно реалізують пари функцій HRTF (для кожного джерела звуку), генеруючи вихідні сигнали, які при відтворенні сприймаються як такі, що випускаються як від положення джерела. Недоліком традиційного заглушення перехресних перешкод є те, що, для відчуття переваг заглушення, слухач повинен залишатися у фіксованому положенні в "зоні найкращого сприйняття". Звичайно зона найкращого сприйняття являє собою положення, у якому гучномовці розташовуються в симетричних положеннях стосовно слухача, хоча можливі й асиметричні положення. 2 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 60 Віртуалізатори можуть реалізовуватися для широкого вибору мультимедійних пристроїв, які містять гучномовці (телевізори, ПК, iPod док-станції) або призначаються для використання зі стереофонічними гучномовцями або навушниками. Існує потреба у віртуалізаторі з низькими вимогами до швидкодії процесора (наприклад, з низьким числом MIPS (мільйон команд у секунду)) і низькими вимогами до пам'яті, а також з поліпшеними акустичними характеристиками. Типові варіанти здійснення даного винаходу досягають покращених акустичних характеристик у сполученні зі зниженими обчислювальними потребами за допомогою нової спрощеної топології фільтра. Також існує потреба у віртуалізаторі оточуючого звуку, який би виділяв віртуалізовані джерела (наприклад, віртуалізовані тилові канали оточуючого звуку) у змішаному вихідному звуковому сигналі, що, якщо буде потреба, визначається вихідними сигналами віртуалізатора (наприклад, коли віртуалізовані джерела генеруються у відповідь на вхідні сигнали низького рівня від тилових джерел), уникаючи при цьому додання надлишкового значення віртуальним каналам (наприклад, уникаючи віртуальних тилових акустичних систем, сприйманих як надмірно голосні). Для досягнення зазначених поліпшених акустичних характеристик при відтворенні вихідних сигналів віртуалізатора, варіанти здійснення даного винаходу в ході генерування віртуалізованих каналів оточуючого звуку (наприклад, віртуалізованих тилових каналів) застосовують динамічне стиснення діапазону. Для забезпечення покращених акустичних характеристик (включаючи поліпшену локалізацію) у ході відтворення вихідних сигналів віртуалізатора, типові варіанти здійснення даного винаходу також застосовують для віртуалізованих джерел декореляцію й заглушення перехресних перешкод. Короткий опис винаходу У деяких варіантах здійснення, винахід являє собою систему та спосіб віртуалізації оточуючого звуку, призначені для генерування вихідних сигналів з метою їхнього відтворення парою фізичних акустичних систем (наприклад, навушників або гучномовців, розташованих у вихідних положеннях) у відповідь на ряд з N вхідних звукових сигналів (де N - число не менше двох), де вхідні звукові сигнали є ознаками звуку з декількох положень джерел, включаючи, щонайменше, два тилових положення. Звичайно, N=5, і вхідні сигнали є ознаками звуку із трьох передніх положень (лівого, центрального та правого передніх положень) і двох тилових положень (лівого оточуючого і правого оточуючого тилових положень). У типових варіантах здійснення винаходу віртуалізатор відповідно до винаходу генерує лівий та правий вихідні сигнали (L' або R') для приведення в дію пари передніх гучномовців у відповідь на п'ять вхідних звукових сигналів: лівий ("L") канал є ознакою звуку з лівого переднього джерела, центральний канал ("С") є ознакою звуку із центрального переднього джерела, правий канал ("R") є ознакою звуку із правого переднього джерела, лівий оточуючий канал ("LS") є ознакою звуку з лівого тилового джерела, а правий оточуючий канал ("RS") є ознакою звуку із правого тилового джерела. Віртуалізатор генерує фантомний центральний канал шляхом поділу вхідного сигналу центрального каналу нарівно між правим та лівим вихідними сигналами. Віртуалізатор включає підсистему віртуалізатора (оточуючого) тилового каналу, сконфігуровану для генерування лівого та правого оточуючих вихідних сигналів (LS' і RS'), які придатні для приведення передніх гучномовців у стан випускання звуку, що слухач сприймає як звук, який випускається джерелами RS і LS за слухачем. Підсистема віртуалізатора оточуючого звуку сконфігурована для генерування вихідних сигналів LS' і RS' у відповідь на вхідні сигнали тилових каналів (LS і RS) шляхом перетворення вхідних сигналів тилових каналів відповідно до функції моделювання сприйняття звуку (HRTF). Віртуалізатор комбінує вихідні сигнали LS' і RS' із вхідними сигналами передніх каналів L, С і R, генеруючи лівий та правий вихідні сигнали (L' і R'). Коли вихідні сигнали L' і R' відтворюються передніми гучномовцями, слухач сприймає кінцевий звук як звук, що випускається тиловими джерелами RS і LS, а також передніми джерелами L, С, і R. В одному із класів варіантів здійснення винаходу, спосіб та система винаходу реалізує модель HRTF, що є простою для реалізації та налаштування для будь-якого положення джерела й положення фізичної акустичної системи щодо кожного з ушей слухача. Переважно, модель HRTF використовується для обчислення узагальненої HRTF, що використовується для генерування лівого і правого оточуючих вихідних сигналів (LS' і RS') у відповідь на вхідні сигнали тилових каналів (LS і RS), а також для обчислення функцій HRTF, які використовуються для виконання заглушення перехресних перешкод на лівому та правому оточуючих вихідних сигналах (LS' і RS') для даного ряду положень фізичних акустичних систем. Для того щоб забезпечити слухачу відтворені віртуальні вихідні сигнали, гарну чутність віртуальних каналів (наприклад, лівого оточуючого і правого оточуючого віртуальних тилових 3 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 60 каналів) у присутності інших каналів, віртуалізатор виконує стиснення динамічного діапазону на вхідних сигналах тилових джерел (у ході генерування у відповідь на вхідні сигнали тилових джерел оточуючих сигналів, використовуваних для приведення передніх гучномовців у стан випускання звуку, що слухач сприймає як звук, який випускається з положень тилових джерел), що сприяє нормалізації сприйманої гучності віртуальних тилових каналів. У даному описі, виконання стиснення динамічного діапазону "на" вхідних сигналах (у ході генерування оточуючих сигналів), у більш широкому сенсі, означає виконання стиснення динамічного діапазону безпосередньо на вхідних сигналах або на оброблених версіях вхідних сигналів (наприклад, на версіях вхідних сигналів, які були піддані декореляції або іншій фільтрації). Для генерування оточуючих сигналів може знадобитися подальша обробка сигналів, підданих стисненню динамічного діапазону, або оточуючі сигнали можуть бути вихідними сигналами засобів стиснення динамічного діапазону. У більш загальному сенсі, вираз "виконання операції" (наприклад, фільтрації, декореляції або перетворення відповідно до HRTF) "на" вхідних сигналах (у ході генерування вхідних сигналів оточуючих сигналів) у даному описі, включаючи формулу винаходу, використовується, у широкому сенсі, для позначення виконання операції безпосередньо на вхідних сигналах або на оброблених версіях вхідних сигналів. Стиснення динамічного діапазону, переважно, виконується шляхом нелінійного підсилення вхідних сигналів (оточуючих) тилових джерел або їх частково оброблених версій (наприклад, підсилення вхідних сигналів тилових джерел нелінійно щодо сигналів передніх каналів). Переважно, у відповідь на вхідні оточуючі сигнали (що є ознаками звуку з лівого оточуючого та правого оточуючого тилових джерел), які не перевищують заздалегідь установлене порогове значення, а також у відповідь на вхідні передні сигнали, вхідні оточуючі сигнали підсилюються щодо передніх сигналів (до оточуючих сигналів застосовується більший коефіцієнт підсилення, ніж до передніх сигналів) перед тим, як вони піддаються декореляції й перетворенню відповідно до функції моделювання сприйняття звуку. Переважно, вхідні оточуючі сигнали (або їх частково оброблені версії) підсилюються нелінійно залежно від величини, на яку вхідні оточуючі сигнали менше порогового значення. Коли вхідні оточуючі сигнали вище порогового значення, вони, як правило, не підсилюються (необов'язково, вхідні передні сигнали й вхідні оточуючі сигнали підсилюються на однакову величину тоді, коли вхідні оточуючі сигнали перевищують порогове значення, наприклад, на величину, що залежить від заздалегідь заданого коефіцієнта стиснення). Стиснення динамічного діапазону відповідно до винаходу може приводити до підсилення вхідних тилових каналів на декілька децибел щодо передніх каналів, що, коли це необхідно, сприяє виводу віртуальних тилових каналів у змішаному вихідному звуковому сигналі (тобто коли вхідні сигнали тилових каналів не перевищують порогове значення) без надлишкового підсилення віртуальних тилових каналів тоді, коли вхідні сигнали тилових каналів перевищують порогове значення (щоб уникнути сприйняття віртуальних тилових акустичних систем як надмірно голосних). В одному із класів варіантів здійснення винаходу, спосіб і система винаходу реалізують декореляцію віртуалізованих джерел з метою забезпечення покращеної локалізації й щоб уникнути труднощів, викликаних симетрією фізичних акустичних систем у присутності віртуальних акустичних систем. За відсутності зазначеної декореляції, якщо фізичні акустичні системи (наприклад, гучномовці перед слухачем) симетричні щодо слухача (наприклад, коли слухач перебуває в зоні найкращого сприйняття), сприймані положення віртуальних акустичних систем також симетричні щодо слухача. У цьому випадку, якщо обидва віртуальних тилових канали (що є ознаками вхідних сигналів лівого оточуючого та правого оточуючого тилових джерел) ідентичні, то відтворені сигнали для обох ушей також ідентичні, і тилові джерела більше не є віртуалізованими (слухач не сприймає відтворений звук як звук, що випускається через спину слухача). Крім того, за відсутності декореляції при симетричному розміщенні фізичних акустичних систем перед слухачем, відтворені вихідні сигнали віртуалізатора у відповідь на панорамування вхідних сигналів тилових джерел (вхідні сигнали є ознаками звуку, панорамованого від лівого оточуючого тилового джерела до правого оточуючого тилового джерела) у середині панорамування джерела звуку будуть здаватися такими, що надходять спереду. Зазначений клас варіантів здійснення винаходу дозволяє уникнути цих проблем (звичайно названих "колапсом зображення") шляхом реалізації декореляції вхідних сигналів (оточуючих) тилових джерел. Декореляція вхідних сигналів тилових джерел у тих випадках, коли вони ідентичні один одному, усуває спільність між ними й дозволяє уникнути колапсу зображення. У типових варіантах здійснення винаходу, система відповідно до винаходу являє собою або містить універсальний або спеціалізований процесор, програмований за допомогою програмного забезпечення (або убудованого програмного забезпечення) та/або інакше 4 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 60 сконфігурований для виконання варіанта здійснення способу винаходу. У деяких варіантах здійснення винаходу, система віртуалізатора відповідно до винаходу являє собою універсальний процесор, що підключений для прийому вхідних даних, що є ознаками вхідних звукових каналів, і програмується (за допомогою належного програмного забезпечення) для генерування вихідних даних, що є ознаками вихідних сигналів (призначених для відтворення парою фізичних акустичних систем) у відповідь на вхідні дані шляхом виконання одного з варіантів здійснення способу винаходу. В інших варіантах здійснення винаходу, система віртуалізатора відповідно до винаходу реалізується шляхом належного конфігурування (наприклад, шляхом програмування) цифрового процесора, що перебудовується, для обробки звуку (DSP). DSP для обробки звуку може являти собою традиційний DSP для обробки звуку, який є таким, що перебудовується (наприклад, програмувальним за допомогою належного програмного забезпечення або вбудованого програмного забезпечення, або інакше конфігурованим у відповідь на керуючі дані) для виконання кожної з великої кількості операцій на вхідних звукових сигналах. У ході роботи, DSP для обробки звуку, сконфігурований для виконання віртуалізації оточуючого звуку відповідно до винаходу, підключається для прийому декількох вхідних звукових сигналів (що є ознаками звуку з декількох положень джерел, включаючи, щонайменше, два тилових положення), і, як правило, DSP виконує ряд операцій на вхідних звукових сигналах крім і на додаток до віртуалізації. Відповідно до різних варіантів здійснення винаходу, DSP для обробки звуку придатний для виконання варіанта здійснення способу винаходу після конфігурування (наприклад, програмування) з метою генерування вихідних звукових сигналів (для відтворення парою фізичних акустичних систем) у відповідь на вхідні звукові сигнали шляхом виконання способу на вхідних звукових сигналах. У деяких варіантах здійснення, винахід являє собою спосіб віртуалізації звуку з метою генерування вихідних сигналів для відтворення парою фізичних акустичних систем, що перебувають у певних фізичних положеннях щодо слухача, де жодне із зазначених положень не є положенням з ряду з, щонайменше, двох положень тилових джерел, при цьому зазначений спосіб включає наступні етапи: (а) у відповідь на вхідні звукові сигнали, що є ознаками звуку з положень тилових джерел генерування оточуючих сигналів, придатних для приведення акустичних систем у певних фізичних положеннях у стан випускання звуку таким чином, щоб слухач сприймав його як звук, що випускається зазначеними положеннями тилових джерел, у тому числі, включаючи виконання стиснення динамічного діапазону на вхідних звукових сигналах; та (b) генерування вихідних сигналів у відповідь на оточуючі сигнали й, щонайменше, ще один вхідний звуковий сигнал, де кожний зазначений ще один вхідний сигнал є ознакою звуку з відповідного положення переднього джерела, так щоб вихідні сигнали були придатні для приведення акустичних систем у певних фізичних положеннях у стан випускання звуку таким чином, щоб слухач сприймав його як звук, що випускається з положень тилових джерел і з кожного зазначеного положення переднього джерела. Як правило, фізичні акустичні системи являють собою передні гучномовці у фізичних положеннях перед слухачем, і етап (а) включає етап генерування лівого та правого оточуючих сигналів (LS' і RS') у відповідь на лівий та правий тилові вхідні сигнали (LS і RS), де лівий та правий оточуючі сигнали (LS' і RS") придатні для приведення передніх гучномовців у стан випускання звуку, який слухач сприймає як звук, що випускається з лівого тилового та правого тилового джерел за слухачем. В альтернативному варіанті, фізичні акустичні системи можуть являти собою навушники або гучномовці, розташовані інакше, ніж у положеннях тилових джерел (наприклад, гучномовці, розташовані ліворуч і праворуч від слухача). Переважно, фізичні акустичні системи є передніми гучномовцями у фізичних положеннях перед слухачем, і етап (а) включає етап генерування лівого і правого оточуючих сигналів (LS' і RS'), придатних для приведення передніх гучномовців у стан випускання звуку, що слухач сприймає як звук, що випускається з лівого тилового і правого тилового джерел за слухачем, а етап (b) включає етап генерування вихідних сигналів у відповідь на: оточуючі сигнали, лівий вхідний звуковий сигнал, що є ознакою звуку з положення лівого переднього джерела, правий вхідний звуковий сигнал, що є ознакою звуку з положення правого переднього джерела, і центральний вхідний звуковий сигнал, що є ознакою звуку з положення центрального переднього джерела. Переважно, етап (b) включає етап генерування фантомного центрального каналу у відповідь на центральний вхідний звуковий сигнал. Переважно, стиснення динамічного діапазону сприяє нормалізації сприйманої гучності віртуальних тилових каналів. Також переважно, щоб стиснення динамічного діапазону виконувалося шляхом підсилення вхідних звукових сигналів нелінійно щодо кожного із зазначених інших вхідних звукових сигналів. Переважно, етап (а) включає етап виконання 5 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 60 стиснення динамічного діапазону, що полягає у підсиленні кожного із вхідних звукових сигналів, що має рівень (наприклад, середній рівень за тимчасовим вікном), що не перевищує заздалегідь задане порогове значення, нелінійно залежно від величини, на яку зазначений рівень менше порогового значення. Переважно, етап (а) включає етап генерування оточуючих сигналів, що полягає в перетворенні вхідних звукових сигналів відповідно до функції моделювання сприйняття звуку (HRTF), та/або шляхом виконання декореляції на вхідних звукових сигналах, та/або шляхом виконання заглушення перехресних перешкод на вхідних звукових сигналах. У даному описі, вираз "виконання" операції (наприклад, перетворення відповідно до HRTF або стиснення динамічного діапазону, або декореляції) "на" вхідних звукових сигналах використовується, у широкому сенсі, для позначення виконання операції на вхідних звукових сигналах або на оброблених версіях вхідних звукових сигналів (наприклад, на версіях вхідних звукових сигналів, які були піддані декореляції або іншій фільтрації). Особливості винаходу включають систему віртуалізатора, сконфігуровану (наприклад, запрограмовану) для виконання будь-якого варіанта здійснення способу винаходу, а також комп'ютерний програмний носій (наприклад, диск), на якому зберігається програмний код для реалізації будь-якого варіанта здійснення способу винаходу. Короткий опис графічних матеріалів Фіг. 1 - блок-схема традиційної системи віртуалізатора оточуючого звуку. Фіг. 2 - блок-схема іншої традиційної системи віртуалізатора оточуючого звуку. Фіг. 3 - блок-схема одного з варіантів здійснення системи віртуалізатора оточуючого звуку відповідно до винаходу. Фіг. 4 - блок-схема реалізації етапу 41 підсистеми віртуалізатора 40 за фіг. 3. Фіг. 5 - блок-схема реалізації етапу 42 підсистеми віртуалізатора 40 за фіг. 3. Фіг. 6 - блок-схема реалізації однієї зі схем HRTF на етапі 43 підсистеми віртуалізатора 40. Фіг. 7 - блок-схема реалізації етапу 44 підсистеми віртуалізатора 40. Фіг. 8 - детальна блок-схема реалізації лімітера 32 системи віртуалізатора за фіг. 3. Фіг. 9 - блок-схема процесора цифрової обробки звукових сигналів (DSP), що представляє собою один з варіантів здійснення системи віртуалізатора оточуючого звуку відповідно до винаходу. Детальний опис переважних варіантів здійснення винаходу Технологічно є здійсненною велика кількість варіантів здійснення даного винаходу. З даного розкриття фахівцям у даній області стане ясно, яким чином їх реалізовувати. Варіанти здійснення системи винаходу, способу винаходу й носія будуть описані з посиланням на фіг. З9. У деяких варіантах здійснення, винахід являє собою спосіб віртуалізації звуку, призначений для генерування вихідних сигналів (наприклад, сигналів L' і R' за фіг. 3) для їхнього відтворення парою фізичних акустичних систем, що перебувають у певних фізичних положеннях щодо слухача, де жодне з фізичних положень не є положенням з ряду з, щонайменше, двох положень тилових джерел, при цьому зазначений спосіб включає наступні етапи: (a) у відповідь на вхідні звукові сигнали (наприклад, лівий та правий тилові вхідні сигнали, LS і RS, фіг. 3), що є ознаками звуку з положень тилових джерел - генерування оточуючих сигналів (наприклад, сигналів оточуючого звуку LS' і RS', фіг. 3), придатних для приведення акустичних систем у фізичних положеннях у стан випускання звуку таким чином, щоб слухач сприймав його як звук, що випускається із зазначених положень тилових джерел, що полягає у виконанні стиснення динамічного діапазону на вхідних звукових сигналах; та (b) генерування вихідних сигналів у відповідь на сигнали оточуючого звуку (наприклад, сигнали оточуючого звуку LS' і RS' за фіг. 3) і, щонайменше, ще один вхідний звуковий сигнал (наприклад, вхідний звуковий сигнал С, L або R за фіг. 3), де кожний зазначений ще один вхідний звуковий сигнал є ознакою звуку з відповідного положення переднього джерела таким чином, щоб вихідні сигнали були придатні для приведення акустичних систем, що перебувають у певних фізичних положеннях, у стан випускання звуку, що слухач сприймає як звук, що випускається з положень тилових джерел і з кожного зазначеного положення переднього джерела. Як правило, фізичні акустичні системи являють собою передні гучномовці в певних фізичних положеннях перед слухачем, і етап (а) включає етап генерування лівого й правого сигналів оточуючого звуку (наприклад, сигналів LS' і RS' за фіг. 3) у відповідь на лівий та правий тилові вхідні сигнали (наприклад, сигнали LS і RS за фіг. 3), де лівий та правий сигнали оточуючого звуку придатні для приведення передніх гучномовців у стан випускання звуку, що слухач сприймає як звук, який випускається з лівого тилового й правого тилового джерел за слухачем. 6 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 Фізичні акустичні системи альтернативно можуть являти собою навушники або гучномовці, розташовані в положеннях, що відрізняються від положень тилових джерел (наприклад, гучномовців, розташованих ліворуч і праворуч від слухача). Переважно, фізичні акустичні системи являють собою передні гучномовці, що перебувають у фізичних положеннях перед слухачем, і етап (а) включає етап генерування лівого й правого сигналів оточуючого звуку (наприклад, LS' і RS' за фіг. 3), придатних для приведення передніх гучномовців у стан випускання звуку, що слухач сприймає як звук, який випускається з лівого тилового та правого тилового джерел за слухачем, а етап (b) включає етап генерування вихідних сигналів у відповідь на: сигнали оточуючого звуку, лівий вхідний звуковий сигнал, що є ознакою звуку з положення лівого переднього джерела, правий вхідний звуковий сигнал, що є ознакою звуку з положення правого переднього джерела й центральний вхідний звуковий сигнал, що є ознакою звуку з положення центрального переднього джерела. Переважно, етап (b) включає етап генерування фантомного центрального каналу у відповідь на центральний вхідний звуковий сигнал. У деяких варіантах здійснення, винахід являє собою спосіб і систему віртуалізації оточуючого звуку, які призначені для генерування вихідних сигналів з метою відтворення парою фізичних акустичних систем (наприклад, навушників або гучномовців, розташованих у певних вихідних положеннях) у відповідь на ряд з N вхідних звукових сигналів (де N - число не менше двох), де вхідні звукові сигнали є ознаками звуку з декількох положень джерел, що включають, щонайменше, два тилових положення. Як правило, N=5, і вхідні сигнали є ознаками звуку із трьох передніх положень (лівого, центрального та правого передніх джерел) і двох тилових положень (лівого оточуючого та правого оточуючих тилових джерел). Фіг. 3 являє собою блок-схему одного з варіантів здійснення системи віртуалізатора відповідно до винаходу. Віртуалізатор за фіг. 3 конфігурується для генерування лівого та правого вихідних сигналів (L' і R'), призначених для приведення в дію пари передніх гучномовців (або інших акустичних систем) у відповідь на п'ять вхідних звукових сигналів: лівого ("L") каналу, що є ознакою звуку з лівого переднього джерела, центрального ("С") каналу, що є ознакою звуку із центрального переднього джерела, правого ("R") каналу, що є ознакою звуку із правого переднього джерела, лівого оточуючого ("LS") каналу, що є ознакою звуку з лівого тилового джерела LS, і правого оточуючого ("RS") каналу, що є ознакою звуку із правого тилового джерела RS. Віртуалізатор генерує фантомний центральний канал (і комбінує його з лівим та правим передніми каналами L і R і віртуальним лівим і віртуальним правим каналами) шляхом підсилення центрального вхідного сигналу С у підсилювачі G, додавання підсиленого вихідного сигналу підсилювача G із вхідним сигналом L і лівим вхідним сигналом оточуючого звуку LS' (буде описано нижче) в елементі 30 додавання для генерування необмеженого лівого вихідного сигналу, і додавання підсиленого вихідного сигналу підсилювача G із вхідним сигналом R і правим оточуючім вихідним сигналом RS' (як буде описано нижче) в елементі 31 додавання для генерування необмеженого правого вихідного сигналу. Необмежені лівий та правий вихідні сигнали обробляються лімітером 32 щоб уникнути насичення. У відповідь на необмежений лівий вихідний сигнал лімітер 32 генерує лівий вихідний сигнал (L'), що направляється до лівої передньої акустичної системи. У відповідь на необмежений правий вихідний сигнал лімітер 32 генерує правий вихідний сигнал (R'), що направляється до правої передньої акустичної системи. Коли вихідні сигнали L' і R' відтворюються передніми гучномовцями, слухач сприймає результуючий звук як звук, що випускається з тилових джерел RS і LS, а також з передніх джерел L, С тa R. Підсистема 40 віртуалізатора (оточуючих) тилових каналів за фіг. 3 генерує лівий та правий оточуючі вихідні сигнали LS' і RS', придатні для приведення передніх акустичних систем у стан випускання звуку таким чином, щоб слухач сприймав його як звук, що випускається із правого тилового джерела RS і лівого тилового джерела LS за слухачем. Підсистема віртуалізатора 40 включає етап 41 стиснення динамічного діапазону, етап 42 декореляції, етап 43 бінауральної моделі (етап HRTF) та етап 44 заглушення перехресних перешкод, які з'єднані так, як показано. Підсистема 40 віртуалізатора генерує вихідні сигнали LS' і RS' у відповідь на вхідні сигнали тилових каналів (LS і RS) шляхом виконання стиснення динамічного діапазону на вхідних сигналах LS і RS на етапі 41, декореляції вихідного сигналу етапу 41 на етапі 42, перетворення вихідного сигналу етапу 42 відповідно до функції моделювання сприйняття звуку (HRTF) на етапі 43 і виконання заглушення перехресних перешкод на вихідному сигналі етапу 43 на етапі 44, вихідними сигналами якого є сигнали LS' i RS'. У варіантах здійснення даного винаходу, де фізичні акустичні системи реалізовані у вигляді навушників, заглушення перехресних перешкод, як правило, не потрібно. Такі варіанти 7 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 60 здійснення винаходу можуть бути реалізовані змінами системи за фіг. 3, у яких етап 44 опущений. Етап 43 HRTF застосовує HRTF, що включає дві передатні функції, HRTFipsi(t) і HRTFcontra(t), до вихідного сигналу етапу 42 так, як описано нижче. У відповідь на декорельований лівий тиловий вхідний сигнал L(t) з етапу 42 (ідентифікований на фіг. 5 як "LS2"), етап 43 генерує звукові сигнали xLL(t) та xLR(t), шляхом наступного застосування передатних функцій: HRTFipsi(t)L(t)= xLL(t), де xLL(t) - звук, чутний лівим вухом слухача (що попадає в ліве вухо слухача), у відповідь на вхідний сигнал L(t), і HRTFcontra(t)L(t) = xLR(t), де xLR(t) - звук, чутний правим вухом слухача (що попадає в праве вухо слухача), у відповідь на вхідний сигнал L(t). Подібним чином, у відповідь на декорельований правий тиловий вхідний сигнал R(t) з етапу 42 (ідентифікований на фіг. 5 як "RS2"), етап 43 генерує звукові сигнали xLR(t) й xRR(t) шляхом наступного застосування передатних функцій: HRTFipsi(t)R(t)= xRL(t), де xRL(t) - звук, чутний лівим вухом слухача у відповідь на вхідний сигнал R(t), і HRTFcontra(t)R(t) = xRR(t), де xRR(t) - звук, чутний правим вухом слухача у відповідь на вхідний сигнал R(t). Таким чином, HRTFipsi(t) являє собою іпсілатеральний фільтр для вуха, найближчого до акустичної системи (яка на етапі 43 є віртуальною акустичною системою), a HRTFcontra(t) - контралатеральний фільтр для вуха, віддаленого від акустичної системи (яка на етапі 43 також є віртуальною акустичною системою). Етап 43 застосовує HRTFipsi(t) до L(t) для генерування звуку, що буде випускатися з лівої передньої акустичної системи й сприйматися лівим вухом як звук L(t) з віртуальної лівої тилової акустичної системи, і застосовує HRTFcontra(t) до L(t) для генерування звуку, що буде випускатися із правої передньої акустичної системи й сприйматися правим вухом як звук L(t) з віртуальної лівої тилової акустичної системи. Етап 43 застосовує HRTFipsi(t) до R(t) для генерування звуку, що буде випускатися із правої передньої акустичної системи й сприйматися правим вухом як звук L(t) з віртуальної правої тилової акустичної системи, і застосовує HRTFcontra(t) до R(t) для генерування звуку, що буде випускатися із правої передньої акустичної системи й сприйматися лівим вухом як звук L(t) з віртуальної правої тилової акустичної системи. Переважно, етап HRTF 43 реалізує модель HRTF, що є простою і такою, що настроюється для будь-яких положень джерел (і, необов'язково, також і для будь-яких положень фізичних акустичних систем) відносно кожного з ушей слухача. Наприклад, етап 43 може реалізовувати модель HRTF, що відноситься до типу, описаному в статті Brown, P., Duda, R., "A Structural Model for Binaural Sound Synthesis", IEEE Transactions on Speech and Audio Processing, September 1998, Vol. 6, No. 5, pp. 476-488. Незважаючи на те, що в цій моделі є недолік деяких тонких особливостей фактично вимірюваної HRTF, вона володіє рядом важливих переваг, які включають простоту її реалізації, настроювання для будь-якого положення й, таким чином, більшу універсальність, ніж у випадку вимірюваної HRTF. У типових реалізаціях, для обчислення узагальнених передатних функцій HRTFipsi(t) і HRTFcontra(t), застосовуваних на етапі 43, використовується та ж модель HRTF, що й для обчислення передатних функцій HRTFITF і HRTFEQF (які будуть описані нижче), застосовуваних на етапі 44 для виконання заглушення перехресних перешкод на вихідних сигналах етапу 43 при заданому ряді положень фізичних акустичних систем. HRTF, застосовувана на етапі 43, припускає певні кути віртуальних тилових акустичних систем; функції HRTF, застосовувані на етапі 44, припускають певні кути фізичних передніх гучномовців стосовно слухача. Етап 41 реалізує стиснення динамічного діапазону, що забезпечує добру чутність лівого оточуючого та правого оточуючого тилових каналів у присутності інших каналів слухачем, що слухає вихідні сигнали, відтворені віртуалізатором за фіг. 3. Етап 41 сприяє виводу низькорівневих віртуальних каналів, які у звичайних умовах маскуються іншими каналами, у результаті чого вміст тилового оточуючого звуку чується частіше й більш надійно, ніж за відсутності стиснення динамічного діапазону. Етап 41 сприяє нормалізації сприйманої гучності віртуальних тилових каналів шляхом підсилення (оточуючих) вхідних сигналів тилових джерел LS і RS нелінійно щодо вхідних сигналів передніх каналів L, R і C. Точніше, у відповідь на визначення того, що вхідний оточуючий сигнал LS не перевищує заздалегідь задане порогове значення, вхідний сигнал LS підсилюється (нелінійно) щодо вхідних сигналів передніх каналів (до сигналу LS застосовується більший коефіцієнт підсилення, ніж до вхідних сигналів передніх каналів), а у відповідь на визначення того, що вхідний сигнал RS не перевищує заздалегідь задане порогове значення, вхідний сигнал RS підсилюється (нелінійно) щодо вхідних сигналів передніх каналів (до сигналу RS застосовується більший коефіцієнт підсилення, ніж до вхідних сигналів передніх каналів). Переважно, вхідні сигнали LS і RS, які не перевищують порогове значення, підсилюються нелінійно залежно від величини (якщо вона має місце), на яку кожний з них нижче порогового значення. Вихідний сигнал етапу 41 потім перетерплює декореляцію на етапі 42. 8 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 60 Якщо хоча б один із вхідних сигналів LS і RS перевищує порогове значення, то він не підсилюється вище величини вхідних передніх сигналів. Точніше, етап 41 підсилює кожний із сигналів LS і RS, що перевищує порогове значення на величину, що залежить від заздалегідь заданого коефіцієнта стиснення, що, як правило, має те ж значення, що й коефіцієнт стиснення, відповідно до якого підсилюються вхідні передні сигнали (за допомогою підсилювача G та інших засобів підсилення, які не показані). Якщо коефіцієнт стиснення являє собою співвідношення N: 1, то рівень підсиленого сигналу в дБ становить NI, где I - рівень вхідного сигнала в дБ. Як правило, здійснюється широкосмугова реалізація етапу 41 (для посилення всіх, або широкого діапазону, частотних складових вхідних сигналів LS і RS), однак, в альтернативному варіанті, можуть бути задіяні багатосмугові реалізації (для підсилення частотних складових вхідних сигналів тільки в певних смугах частот, або підсилення частотних складових вхідних сигналів по-різному в різних смугах частот). Коефіцієнт стиснення та порогове значення вибираються способом, що відомий фахівцям у даній області, так, щоб етап 41 робив типовий, низькорівневий вміст навколишнього звуку чітко чутним (у змішаному вихідному звуковому сигналі, обумовленому вихідним сигналом віртуалізатора за фіг. 3). Фіг. 4 являє собою блок-схему типової реалізації етапу 41, що включає елемент 70 визначення середньоквадратичної потужності (RMS), елемент 71 визначення плавності, елемент 72 обчислення коефіцієнта підсилення й елементи 73 і 74 підсилення, з'єднані так, як показано на фіг. 4. У даній реалізації, середній рівень (середня гучність, усереднена за інтервалом часу, тобто за заздалегідь заданим тимчасовим вікном) кожного вхідного LS і RS визначається в елементі 70, а плавність вихідного сигналу етапу 41 (швидкість, з якою елемент 72 обчислення коефіцієнта підсилення змінює коефіцієнт підсилення, який застосовується підсилювачами 73 і 74 до кожного вхідного сигналу у відповідь на кожне збільшення й зменшення середнього рівня вхідного сигналу) визначається елементом 71 у відповідь на середні рівні вхідних сигналів і коефіцієнт підсилення, який застосовується до кожного вхідного сигналу. Типовий час наростання (постійна часу відгуку на збільшення рівня вхідного сигналу) становить 1 мс, а типовий час загасання (постійна часу відгуку на зменшення рівня вхідного сигналу) становить 250 мс. Елемент 72 обчислення коефіцієнта підсилення визначає величину коефіцієнта підсилення, що застосовується підсилювачем 73 до вхідного сигналу LS (для генерування підсиленого вихідного сигналу LS 1) залежно від величини, на яку поточний середній рівень LS перевищує або не перевищує порогове значення (і від поточного часу наростання й часу загасання), а також величину коефіцієнта підсилення, який застосовується підсилювачем 74 до вхідного сигналу RS (для генерування підсиленого вихідного сигналу RS1) залежно від величини, на яку поточний середній рівень RS перевищує або не перевищує порогове значення (і від поточного часу наростання й часу загасання). Типове порогове значення становить 50 % повної шкали, а типовий коефіцієнт стиснення становить 2:1 для підсилення кожного вхідного сигналу, коли його рівень вище порогового значення. В типових реалізаціях стиснення динамічного діапазону на етапі 41 підсилює тилові вхідні канали на декілька децибел відносно передніх вхідних каналів для того, щоб допомогти виділити віртуальні тилові канали в змішаному вихідному звуковому сигналі в тих випадках, коли їхні рівні досить низькі для того, щоб зробити бажаним їхнє виділення (тобто коли тилові вхідні сигнали не перевищують заздалегідь задане порогове значення), уникаючи при цьому надлишкового підсилення віртуальних тилових каналів тоді, коли вхідні сигнали тилових каналів перевищують порогове значення (щоб уникнути сприйняття віртуальних тилових акустичних систем як надмірно голосних). Етап 42 декорелює лівий та правий вихідні сигнали етапу 41, забезпечуючи покращену локалізацію й перешкоджаючи виникненню труднощів, які можуть бути пов'язані із симетрією (у відношенні до слухача) фізичних акустичних систем, які представляють віртуальні канали, обумовлені вихідним сигналом віртуалізатора за фіг. 3. За відсутності такої декореляції, якщо фізичні гучномовці (перед слухачем) розташовуються симетрично стосовно слухача, то положення, що сприймаються, віртуальних акустичних систем також симетричні стосовно слухача. При такій симетрії й за відсутності декореляції, якщо обидва віртуальних тилових канали (що є ознаками тилових вхідних сигналів LS і RS) ідентичні, відтворені сигнали на обох вухах також будуть ідентичними, і тилові джерела більше не будуть віртуалізованими (слухач не буде сприймати відтворений звук як звук, що випускається джерелами за слухачем). Крім того, при такій симетрії за відсутності декореляції відтворюваний вихідний сигнал віртуалізатора у відповідь на панорамування вхідного сигналу тилового джерела (вхідного сигналу, що є ознакою звуку, панорамованого від лівого оточуючого тилового джерела до правого оточуючого тилового джерела) у середині панорамування буде здаватися таким, що надходить 9 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 60 безпосередньо спереду (між фізичними передніми акустичними системами). Етап 42 дозволяє уникнути цих труднощів (звичайно названих "колапсом зображення") шляхом декореляції лівого та правого вихідних сигналів етапу 41 у випадку, коли вони ідентичні один одному, усуваючи спільність між ними й, таким чином, дозволяючи уникнути колапсу зображення. На етапі декореляції 42 для декореляції двох вихідних сигналів етапу 41 використовуються додаткові декорелятори (по одному декорелятору на кожний із сигналів LS 1 і RS1). Кожний декорелятор, переважно, реалізується як ревербератор Шредера, що пропускає всі частоти, що відноситься до типу, описаному в статті Schroeder, M. R., "Natural Sounding Artificial Reverberation", Journal of the Audio Engineering Society, July 1962, vol. 10, No. 3, pp. 219-223. У тих випадках, коли активний тільки один вхідний канал, етап 42 не вносить у його вхідний сигнал ніякої помітної зміни тембру. Коли активні обидва вхідних канали, і джерела кожного каналу ідентичні, етап 42 вносить зміну тембру, але його дія така, що стереозображення стає широким, а не панорамованим у центр. Фігура 5 являє собою блок-схему типової реалізації етапу 42 у вигляді пари ревербераторів Шредера, що пропускають всі частоти. Один з ревербераторів у реалізації за фіг. 5 являє собою контур зворотного зв'язка, що включає елемент 80 додавання вхідного сигналу, що містить вхід, підключений для прийому лівого вхідного сигналу LS1 з етапу 41, вихідний сигнал якого направляється до елемента 83 затримки, що застосовує до нього затримку , і до підсилювача 81, що застосовує до нього коефіцієнт підсилення G. Вихідний сигнал цього підсилювача направляється до елемента 82 додавання вихідного сигналу (до якого також направляється вихідний сигнал елемента 83 затримки), що виводить лівий сигнал LS 2. Вихідний сигнал елемента 83 затримки направляється до іншого підсилювача 84, що застосовує до нього коефіцієнт підсилення G - 1, і вихідний сигнал підсилювача 84 направляється до другого входу елемента 80 додавання вхідного сигналу. Другий ревербератор у реалізації етапу 42 за фіг. 5 являє собою контур зворотного зв'язка, що включає елемент 90 додавання вхідного сигналу, що містить вхід, підключений для прийому правого вхідного сигналу RS1 з етапу 41, вихідний сигнал якого направляється до елемента 93 затримки, що застосовує до нього затримку , і до підсилювача 91, що застосовує до нього коефіцієнт підсилення - G. Вихідний сигнал підсилювача 91 направляється до елемента 92 додавання вихідного сигналу (до якого також направляється вихідний сигнал елемента 93 затримки), що виводить правий сигнал RS2 (сигнал RS2 декорельований із сигналом LS2). Вихідний сигнал елемента 93 затримки направляється до другого підсилювача 94, що застосовує до нього коефіцієнт підсилення 1 - G, а вихідний сигнал підсилювача 94 направляється до другого входу елемента 90 додавання вхідного сигналу. Типове значення параметра підсилення G=0,5, типове значення часу затримки = 2 мс. В інших реалізаціях етап 42 являє собою декорелятор, що відноситься до іншого типу, ніж декорелятор, описаний з відсиланням до фіг. 5. У типовій реалізації, етап 43 бінауральної моделі включає дві схеми HRTF, що відносяться до типу, показаного на фіг. 6: одна підключається для фільтрації лівого сигналу LS2 з етапу 42; друга - для фільтрації правого сигналу RS2 з етапу 42. Як видно на фіг. 6, кожна схема HRTF застосовує дві передатні функції, HRTFipsi(z) і HRTFcontra(z), до вихідного сигналу етапу 42, як викладено нижче (де "z" - значення дискретного тимчасового інтервалу сигналу, підданого фільтрації). Кожна з передатних функцій, HRTFipsi(z) і HRTFcontra(z), реалізує просту однополюсну двійкову сферичну модель сприйняття звуку, що відноситься до типу, описаному в процитованій вище статті Brown та ін., "A Structural Model for Binaural Sound Synthesis, " IEEE Transactions on Speech and Audio Processing, September 1998. Точніше, кожна схема HRTF етапу 43 (реалізована, як описано на фіг. 6) застосовує дві передатні функції, HRTFipsi(z) («HRTFipsi(z)») і HRTFcontra(z) («HRTFcontra(z)»), до кожного вихідного сигналу етапу 42 (сигналу, відзначеному на фіг. 6 як "IN") у дискретному тимчасовому інтервалі, як описано нижче. У відповідь на лівий тиловий вхідний сигнал L 2(z) етапи 42, одна схема HRTF генерує звукові сигнали xLL(z) ("OUTIpsi" на фіг. 6) і xLR(z) ("OUTContra" на фіг. 6) шляхом наступного застосування передатних функцій: HRTFipsi(z)L2(z)= xLL(z), де xLL(z) - звук, чутний лівим вухом слухача у відповідь на вхідний сигнал L2(z), і HRTFcontra(z)L2(z)= xLR(z), де xLR(z) звук, чутний правим вухом слухача у відповідь на вхідний сигнал L2(z). У відповідь на правий тиловий вхідний сигнал R 2(z) етапа 42 друга схема HRTF на етапі 43 (реалізована, як показано на фіг. 6) генерує звукові сигнали xLR(z) й xRR(z), шляхом наступного застосування передатних функцій: HRTFcontra(z)L2(z)= xRL(z), де xRL(z) - звук, чутний лівим вухом слухача у відповідь на вхідний сигнал R2(z), і HRTFipsi(z)R2(z)= xRR(z), де xRR(z) - звук, чутний правим вухом слухача у відповідь на вхідний сигнал R 2(z). HRTFipsi(z) являє собою іпсілатеральний фільтр для вуха, найближчого до акустичної системи (яка на етапі 43 є віртуальною акустичною системою), а HRTFcontra(z) є контралатеральним фільтром для вуха, віддаленого від акустичної системи (яка 10 UA 101542 C2 5 10 15 20 25 на етапі 43 також є віртуальною акустичною системою). Віртуальні акустичні системи –n встановлюються під кутом, приблизно, ±90°. Тимчасові затримки z (реалізовані кожним з –n елементів затримки, які на фіг. 6 позначені як z ) так само, як і звичайно, відповідають 90°. Схема HRTF етапу 43 (реалізована, як показано на фіг. 6) для застосування передатної функції HRTFipsi(z) включає елемент 103 затримки, елементи 101, 104 і 105 підсилення (для застосування обумовлених нижче коефіцієнтів підсилення, bi0, bi1 і ai1 відповідно) і елементи 100 і 102 додавання, підключені так, як показано на фіг. 6. Схема HRTF етапу 43 (реалізована, як показано на фіг. 6) для застосування передатної функції HRTF contra(z) включає елементи 106 і 113 затримки, елементи 111, 114 і 115 підсилення (для застосування обумовлених нижче коефіцієнтів підсилення bc0, bc1 і ac1 відповідно) і елементи додавання 110 і 112, підключені так, як показано на фіг. 6. Інтерауральна тимчасова затримка (ITD), реалізована на етапі 43 (реалізованому так, як показано на фіг. 6), являє собою затримку, що вводиться кожним елементом затримки, –n" позначуваним "z . Інтерауральна тимчасова затримка для горизонтальної площини виходить у такий спосіб: (1), ITD=(a/c) (arcsin(cos sin) + cos sin де θ - азимутальний кут, φ - кут підняття, а - радіус голови слухача, с - швидкість звуку. Слід зазначити, що, для обчислення ITD, кути в рівнянні (1) виражаються в радіанах (а не в градусах). Також слід зазначити, що θ = 0 радіан (0°) - це прямо, а θ = /2 (90°) - це строго праворуч. Для φ = 0 (горизонтальна площина): (2), ITD=(a/c) ( + sin) де θ перебуває в діапазоні 0-/2 включно. У безперервному тимчасовому інтервалі модель HRTF, реалізована фільтром за фіг. 6, виражається в такий спосіб: a()s (3), H(s, ) s 2c a , - азимутальний кут, а - радіус голови слухача, с - швидкість де a() =1+cos()й звуку, як і зазначено вище, s - значення безперервного тимчасового інтервалу вхідного сигналу. Для перетворення цієї моделі HRTF до дискретного тимчасового інтервалу (де z - це значення дискретного тимчасового інтервалу вхідного сигналу) використовується білінійне перетворення: (4). 30 Якщо параметр β з рівняння (4) довизначити як 2c a fs , де fs - частота дискретизації, то, отже, H( z ) ( 2a()) ( 2a())z 1 ( 2) ( 2)z 1 b b1z 1 0 a 0 a1z 1 (5), (6). Фільтр відповідно до рівняння (6) призначений для звуку, що попадає в одне вухо слухача. Для двох ушей (ближнього та дальнього стосовно джерела), іпсілатеральний та контралатеральний фільтри за фіг. 6 визначаються з рівняння (6) у такий спосіб: 11 UA 101542 C2 b b i1z 1 Hipsi ( z ) i0 a i0 a i1z 1 (іпсілатеральний, ближнє ухо) b b c1z 1 Hcontra ( z ) c 0 a c 0 a c1z 1 5 10 15 20 25 30 (контралатеральний, дальнє (7), (8), вухо) де (9) a0 =ai0 =ac0 = + 2, (10) a1 =ai1 =ac1 = - 2, (11) bi0 = + 2ai(), (12) bi1 = - 2ai(), (13) bc0 = + 2ac(), (14) bc1 = - 2ac(), (15), і ai() = 1 + cos( - 90) = 1 + sin() (16) ac() = 1 + cos( + 90) = 1 - sin() В альтернативних варіантах здійснення винаходу, кожна застосовувана HRTF (або кожна HRTF з підмножини застосовуваних HRTF), що застосовується відповідно до винаходу, визначається й застосовується в частотній області (наприклад, кожний сигнал, що піддається перетворенню відповідно до зазначеного HRTF, піддається перетворенню з тимчасового інтервалу до частотної області, потім до результуючих частотних складових застосовується HRFT, і перетворені складові потім піддаються перетворенню від частотної області до тимчасового інтервалу). Фільтрований вихідний сигнал етапу 43 піддається заглушенню перехресних перешкод на етапі 44. Заглушення перехресних перешкод є традиційною операцією. Наприклад, реалізація заглушення перехресних перешкод у віртуалізаторі оточуючого звуку описана в патенті США №6 449 368, переуступленому Dolby Laboratories Licensing Corporation, з відсиланням до фіг. 4А цього патенту. Етап 44 заглушення перехресних перешкод у варіанті здійснення винаходу за фіг. 3 фільтрує вихідний сигнал етапу 43, застосовуючи для цього дві передатні функції HITF (фільтри 52 і 53, підключені так, як показано на фіг. 3) і дві передатні функції HEQF (фільтри 50 і 51, підключені так, як показано на фіг. 3). Кожна передатна функція HITF й HEQF реалізує ту ж однополюсну двійкову сферичну модель сприйняття звуку, що й модель, описана в процитованій вище статті Brown та ін. ("A Structural Model for Binaural Sound Synthesis", IEEE Transactions on Speech and Audio Processing, September 1998) і реалізована передатними функціями HRTFipsi(z) й HRTFcontra(z) на етапі 43. -m На етапі 44 варіанта здійснення винаходу за фіг. 3 тимчасова затримка z застосовується до вихідного сигналу фільтра 52 HITF за допомогою елемента 55 затримки за фігурою 7, комбінується з вихідними сигналами xLL(z) й xRL(z) етапу 43 в елементі додавання, і вихідний -m сигнал цього елемента додавання перетворюватися у фільтрі 50 HEQF. Тимчасова затримка z також застосовується до вихідного сигналу фільтра 53 HITF за допомогою елемента 56 затримки за фігурою 7, комбінується з вихідними сигналами xLR(z) й xRR(z) етапу 43 у другому елементі додавання, і вихідний сигнал другого елемента додавання перетвориться у фільтрі 51 HEQF. Вихідний сигнал xLL(z) етапу 43 перетвориться у фільтрі 52 HITF, а вихідний сигнал xRR(z) етапу 43 перетвориться у фільтрі 53 HITF. У фільтрах 50, 51, 52, та 53 кути акустичних систем -m установлюються в положення фізичних акустичних систем. Затримки (z ) визначаються відповідними кутами. Фільтр перехресних перешкод і фільтри вирівнювання HITF й HEQF мають наступну форму: b c 0 b c1 1 z Hc ( z) b c 0 b c1z 1 b b i0 HITF ( z) i0 b Hi ( z) bi0 bi1z 1 1 i1 z 1 b i0 (17), a0 a 1 z 1 a a1z b bi0 1 HEQF ( z ) 0 i0 b i1 1 Hi ( z) bi0 bi1z 1 1 z bi0 (18), 1 12 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 60 де a і b - ті ж параметри, що й у вищенаведених рівняннях (9) - (16). Якщо сума сигналів, що входять в елемент 30 (або 31) за фіг. 3 більше максимально припустимого рівня, може виникнути кліпування. Однак, щоб уникнути подібного відсічення, використовується лімітер 32 за фіг. 3. Лівий оточуючий вихідний сигнал LS' етапу 44 комбінується з підсиленим вхідним сигналом центрального каналу С і лівим переднім вхідним сигналом L в елементі додавання лівого каналу 30, і вихідний сигнал елемента 30 піддається обмеженню в лімітері 32 так, як показано на фіг. 3. Правий оточуючий вихідний сигнал RS' етапу 44 комбінується з підсиленим вхідним сигналом центрального каналу С і правим переднім вхідним сигналом R в елементі додавання правого каналу 31, і вихідний сигнал елемента 31 також піддається обмеженню в лімітері 32 так, як показано на фіг. 3. У відповідь на необмежений лівий вихідний сигнал елемента 30, лімітер 32 генерує лівий вихідний сигнал (L'), що направляється до лівої передньої акустичної системи. У відповідь на необмежений лівий вихідний сигнал елемента 31, лімітер 32 генерує правий вихідний сигнал (R'), що направляється до правої передньої акустичної системи. Лімітер за фіг. 3 може бути реалізований так, як показано на фіг. 8. Лімітер 32 за фіг. 8 має ту ж конструкцію, що й на етапі 41 реалізації стиснення динамічного діапазону, і включає елемент 170 визначення середньоквадратичної потужності, елемент 171 визначення плавності, елемент 172 обчислення коефіцієнта підсилення й елементи 173, 174 підсилення, підключені так, як показано на фіг. 3. Замість підняття низьких рівнів вхідних сигналів, елементи підсилення 173, 174 лімітера 32 знижують максимальні рівні вхідних сигналів (коли рівень хоча б одного із вхідних сигналів перевищує заздалегідь задане порогове значення). Типові час наростання та час загасання для лімітера 32 за фіг. 8 становлять 22 мс та 50 мс відповідно. Типова величина заздалегідь визначеного порогового значення, що використовується в лімітері 32 становить 25 % повної шкали, а типовий коефіцієнт стиснення становить 2:1 для підсилення кожного вхідного сигналу, коли його рівень перевищує порогове значення. У деяких варіантах здійснення винаходу, система віртуалізатора відповідно до винаходу являє собою або містить у собі універсальний процесор, підключений для прийому або генерування вхідних даних, що є ознаками декількох звукових вхідних каналів, і програмувальний за допомогою програмного забезпечення (або убудованого програмного забезпечення) та/або інакше конфігурований (наприклад, у відповідь на керуючі дані) для виконання однієї або ряду операцій на вхідних даних, включаючи варіант здійснення способу винаходу. Зазначений універсальний процесор, як правило, може підключатися до пристрою уведення (наприклад, до миші та/або клавіатури), пам'яті або пристрою відображення. Наприклад, система за фіг. 3 може бути реалізована в універсальному процесорі, де вхідні дані C, L, R, LS і RS являють собою дані, що є ознаками центрального, лівого переднього, правого переднього, лівого тилового й правого тилового звукових вхідних каналів, а вихідні дані L' і R' являють собою вихідні дані, що є ознаками вихідних звукових сигналів. Традиційний цифроаналоговий перетворювач (DAC) може діяти на ці вихідні дані й генерувати аналогові версії вихідних звукових сигналів, призначені для відтворення парою фізичних передніх акустичних систем. Фігура 9 являє собою блок-схему системи 20 віртуалізатора, що є програмувальним DSP для обробки звуку, сконфігурованим для виконання варіанта здійснення способу винаходу. Система 20 включає програмувальну схему 22 DSP (підсистему віртуалізатора системи 20), підключену для прийому вхідних звукових сигналів, що є ознаками звуку з декількох положень джерел, що включають, щонайменше, два тилових положення (наприклад, п'яти звукових сигналів C, L, LS RS та R, як показано на фіг. 3). Схема 22 конфігурується у відповідь на керуючі дані інтерфейсу 21 пристрою керування для виконання варіанта здійснення способу винаходу з метою генерування лівого та правого каналів вихідних звукових сигналів L' й R' та їхнього відтворення парою фізичних акустичних систем у відповідь на вхідні звукові сигнали. Для програмування системи 20 до інтерфейсу 21 пристрою керування направляється належне програмне забезпечення, а інтерфейс 21 направляє належні керуючі дані до схеми 22 для виконання способу винаходу. У ході роботи, DSP для обробки звуку, сконфігурований для виконання віртуалізації оточуючого звуку відповідно до винаходу (наприклад, система 20 віртуалізатора за фіг. 9), підключається для прийому декількох вхідних звукових сигналів (що є ознаками звуку з декількох положень джерел, що включають, щонайменше, два тилових положення) і DSP, як правило, виконує ряд операцій на вхідних звукових сигналах крім і на додаток до віртуалізації. Відповідно до різних варіантів здійснення винаходу, DSP для обробки звуку стає придатним для виконання одного з варіантів здійснення способу винаходу після конфігурування (наприклад, програмування) з метою генерування вихідних звукових сигналів (для їхнього відтворення 13 UA 101542 C2 5 10 15 20 25 30 35 40 45 50 55 60 парою фізичних акустичних систем) у відповідь на вхідні звукові сигнали шляхом виконання способу на вхідних звукових сигналах. Незважаючи на те, що в даному розкритті описані деякі варіанти здійснення даного винаходу й застосування винаходу, фахівці в даній області повинні розуміти, що можлива велика кількість змін описаних тут варіантів здійснення винаходу й застосувань винаходу без відступу від обсягу винаходу, описаного й заявленого в даному розкритті. Варто розуміти, що, незважаючи на те, що були показані й описані деякі варіанти винаходу, винахід не обмежується описаними конкретними варіантами здійснення винаходу або описаних конкретних способів. ФОРМУЛА ВИНАХОДУ 1. Спосіб віртуалізації оточуючого звуку для одержання вихідних сигналів з метою їхнього відтворення парою фізичних акустичних систем, що перебувають у певних фізичних положеннях стосовно слухача, де жодне з фізичних положень не є положенням з ряду положень тилових джерел, де зазначений спосіб включає наступні етапи на яких: (a) у відповідь на вхідні звукові сигнали, що є ознаками звуку з положень тилових джерел, генерують оточуючі сигнали, придатні для приведення акустичних систем у певних фізичних положеннях у стан випускання звуку, сприйманого слухачем як звук, що випускається із зазначених положень тилових джерел, що полягає у стисненні динамічного діапазону на вхідних звукових сигналах, та (b) генерують вихідні сигнали у відповідь на оточуючі сигнали й щонайменше ще один вхідний звуковий сигнал, де кожний зазначений ще один вхідний звуковий сигнал є ознакою звуку з відповідного положення переднього джерела, так, щоб вихідні сигнали були придатні для приведення акустичних систем у певних фізичних положеннях у стан випускання звуку, що слухач сприймає як звук, що випускається з положень тилових джерел і з кожного зазначеного положення переднього джерела. 2. Спосіб за п. 1, який відрізняється тим, що стиснення динамічного діапазону виконують шляхом нелінійного підсилення вхідних звукових сигналів. 3. Спосіб за будь-яким з пп. 1-2, який відрізняється тим, що етап (а) включає етап виконання стиснення динамічного діапазону, що включає підсилення кожного із вхідних звукових сигналів, що має рівень, що не перевищує заздалегідь задане порогове значення, нелінійно залежно від величини, на яку цей рівень менше порогового значення. 4. Спосіб за п. 3, який відрізняється тим, що рівень являє собою середній, за тимчасовим вікном, рівень зазначеного кожного із вхідних звукових сигналів. 5. Спосіб за будь-яким з пп. 1-4, який відрізняється тим, що фізичні акустичні системи являють собою передні гучномовці, які перебувають у певних фізичних положеннях перед слухачем, і етап (а) включає етап генерування лівого та правого оточуючих сигналів у відповідь на лівий та правий тилові вхідні сигнали. 6. Спосіб за п. 5, який відрізняється тим, що етап (b) включає етап генерування вихідних сигналів у відповідь на оточуючі сигнали й у відповідь на лівий вхідний звуковий сигнал, що є ознакою звуку з положення лівого переднього джерела, правий вхідний звуковий сигнал, що є ознакою звуку з положення правого переднього джерела і центрального вхідного звукового сигналу, що є ознакою звуку з положення центрального переднього джерела. 7. Спосіб за п. 6, який відрізняється тим, що етап (b) включає етап генерування фантомного центрального каналу у відповідь на центральний вхідний звуковий сигнал. 8. Спосіб за будь-яким з пп. 1-7, який відрізняється тим, що етап (а) включає етап генерування оточуючих сигналів, що включає перетворення вхідних звукових сигналів відповідно до функції моделювання сприйняття звуку. 9. Спосіб за п. 8, який відрізняється тим, що вхідні звукові сигнали являють собою лівий тиловий вхідний сигнал, що є ознакою звуку з лівого тилового джерела, і правий тиловий вхідний сигнал, що є ознакою звуку із правого тилового джерела, і етап (а) включає наступні етапи, на яких: перетворюють лівий тиловий вхідний сигнал відповідно до функції моделювання сприйняття звуку для генерування першого віртуалізованого звукового сигналу, що є ознакою звуку з лівого тилового джерела, як такого, що попадає в ліве вухо слухача, і другого віртуалізованого звукового сигналу, що є ознакою звуку з лівого тилового джерела, як такого, що попадає в праве вухо слухача, та перетворюють правий тиловий вхідний сигнал відповідно до функції моделювання сприйняття звуку для генерування третього віртуалізованого звукового сигналу, що є ознакою звуку із правого тилового джерела, як такого, що попадає в ліве вухо слухача, і четвертого 14 UA 101542 C2 5 10 15 20 25 30 35 40 віртуалізованого звукового сигналу, що є ознакою звуку із правого тилового джерела, як такого, що попадає в праве вухо слухача. 10. Спосіб за будь-яким з пп. 1-9, який відрізняється тим, що етап (а) включає етап генерування оточуючих сигналів, що включає виконання декореляції на вхідних звукових сигналах. 11. Спосіб за будь-яким з пп. 1-10, який відрізняється тим, що етап (а) включає етап генерування оточуючих сигналів, що включає виконання заглушення перехресних перешкод на вхідних звукових сигналах. 12. Спосіб за п. 1, який відрізняється тим, що фізичні гучномовці являють собою навушники, і етап (а) виконують без виконання заглушення перехресних перешкод на вхідних звукових сигналах. 13. Спосіб за п. 1, який відрізняється тим, що етап (а) включає наступні етапи, на яких: виконують стиснення динамічного діапазону на вхідних звукових сигналах з метою генерування стиснених звукових сигналів, виконують декореляцію на стиснених звукових сигналах з метою генерування декорельованих звукових сигналів, перетворюють декорельовані звукові сигнали відповідно до функції моделювання сприйняття звуку з метою генерування віртуалізованих звукових сигналів, та виконують заглушення перехресних перешкод на віртуалізованих звукових сигналах з метою генерування оточуючих сигналів. 14. Система віртуалізації оточуючого звуку, що сконфігурована для одержання вихідних сигналів з метою їхнього відтворення парою фізичних акустичних систем, що перебувають у певних фізичних положеннях стосовно слухача, яка відрізняється тим, що жодне з фізичних положень не є положенням з ряду положень тилових джерел, що містить: підсистему (40) віртуалізатора оточуючого звуку, підключену й сконфігуровану для генерування оточуючих сигналів у відповідь на вхідні звукові сигнали, що полягає у виконанні стиснення динамічного діапазону на вхідних звукових сигналах, де вхідні звукові сигнали є ознаками звуку з положень тилових джерел, а оточуючі сигнали придатні для приведення акустичних систем у певних фізичних положеннях у стан випускання звуку, що слухач сприймає як звук, що випускається із зазначених положень тилових джерел, та другу підсистему (30, 31), підключену й сконфігуровану для генерування вихідних сигналів у відповідь на оточуючі сигнали й щонайменше ще одного вхідного звукового сигналу, де кожний зазначений ще один вхідний звуковий сигнал є ознакою звуку з відповідного положення переднього джерела, так, щоб вихідні сигнали були придатні для приведення акустичних систем, що перебувають у певних фізичних положеннях, у стан випускання звуку, що слухач сприймає як звук, що випускається з положень тилових джерел і з кожного зазначеного положення переднього джерела. 15. Система за п. 14, яка відрізняється тим, що підсистема (40) віртуалізатора оточуючого звуку сконфігурована для виконання стиснення динамічного діапазону шляхом нелінійного підсилення вхідних звукових сигналів. 15 UA 101542 C2 16 UA 101542 C2 17 UA 101542 C2 18 UA 101542 C2 19 UA 101542 C2 Комп’ютерна верстка Л.Литвиненко Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 20
ДивитисяДодаткова інформація
Назва патенту англійськоюSurround sound virtualizer and method with dynamic range compression
Автори англійськоюBrown, C., Phillip
Назва патенту російськоюВиртуализатор окружающего звука с динамическим сжатием диапазона и способ
Автори російськоюБраун К. Филлип
МПК / Мітки
Мітки: стисненням, віртуалізатор, динамічним, спосіб, діапазону, оточуючого, звуку
Код посилання
<a href="https://ua.patents.su/22-101542-virtualizator-otochuyuchogo-zvuku-z-dinamichnim-stisnennyam-diapazonu-jj-sposib.html" target="_blank" rel="follow" title="База патентів України">Віртуалізатор оточуючого звуку з динамічним стисненням діапазону й спосіб</a>
Спосіб пасивної звуколокації нестаціонарного джерела звуку

Номер патенту: 65809
Опубліковано: 15.04.2004
Автор: Степанченко Сергій Іванович
МПК: G01S 3/00
Мітки: нестаціонарного, звуколокації, пасивної, спосіб, звуку, джерела
Формула / Реферат:
Спосіб пасивної звуколокації нестаціонарного джерела звуку, згідно з яким визначають наявність сигналу від джерела звуку у точках прийому по перевищенню рівнем сигналу, що приймається, відомої заданої величини, сигнал приймають та реєструють у парах просторово рознесених точок з відомими координатами, кількість пар точок прийому сигналу встановлюють не менше розмірності системи координат, що використовується для відображення розташування...
Спосіб визначення інтенсивності звуку на поверхні джерела шуму

Номер патенту: 44177
Опубліковано: 25.09.2009
Автор: Гузь Борис Олександрович
МПК: G01H 1/00
Мітки: шуму, звуку, визначення, джерела, поверхні, спосіб, інтенсивності
Формула / Реферат:
Спосіб визначення інтенсивності звуку на поверхні джерела шуму, що включає вимірювання звукового тиску приймачем звуку і швидкості коливань приймачем віброшвидкості, встановленим на поверхні джерела, який відрізняється тим, що звуковий тиск визначають безпосередньо на поверхні джерела шуму, а приймач звуку ізолюють від дії шуму сторонніх джерел, для чого приймач звуку встановлюють на кінці вузької труби, перпендикулярної до поверхні джерела...
Спосіб визначення інтенсивності звуку на поверхні джерела шуму

Номер патенту: 57886
Опубліковано: 10.03.2011
Автор: Гузь Борис Олександрович
МПК: G01H 1/12, G01H 17/00
Мітки: звуку, джерела, визначення, інтенсивності, спосіб, шуму, поверхні
Формула / Реферат:
Спосіб визначення інтенсивності звуку на поверхні джерела шуму, що включає вимірювання швидкості коливань приймачем віброшвидкості, встановленим на поверхні джерела, і визначення звукового тиску безпосередньо на поверхні джерела шуму двома приймачами звуку, ізольованими від дії шуму сторонніх джерел, для чого приймачі встановлені у вузьких трубах, перпендикулярних до поверхні джерела шуму, інші кінці яких з'єднані з поверхнею джерела, який...
Спосіб визначення швидкості звуку в матеріалах

Номер патенту: 36495
Опубліковано: 16.04.2001
Автори: Поліщук Аркадій Петрович, Бабак Віталій Павлович, Аль Тбарі Крішан Монзер Мухамед С, Філоненко Сергій Федорович
МПК: G01N 29/07, G01H 5/00
Мітки: визначення, звуку, спосіб, матеріалах, швидкості
Текст:
...На фіг. 2 - збудження та перший вступ відбитого сигналу: 3 - сигнал збудження, 4 - вступ відбитого сигналу при відсутності дисперсії швидкості звуку, l - віддаль, яку проходить ультразвуковий імпульс скрізь матеріал; C - швидкість ультразвукових коливань, при відсутності дисперсії звуку; 5 - вступ відбитого сигналу при присутності дисперсії швидкості звуку, l - віддаль, яку проходить ультразвуˆ ковий імпульс скрізь матеріал; C - середня...
Пристрій світловипромінювального діода (свд) іч-діапазону, датчик, що включає в себе пристрій свд іч-діапазону,спосіб приведення в дію свд іч-діапазону та спосіб роботи датчика, що містить свд іч-діапазону

Номер патенту: 57845
Опубліковано: 15.07.2003
Автори: Ешлі Тімоті, Краудер Джон Грехем, Сміт Стенлі Дезмонд, Маннхайм Фолькер Пауль
МПК: G01N 21/01, G01J 3/00, H01L 33/00, G01N 21/35
Мітки: свд, світловипромінювального, приведення, включає, іч-діапазону,спосіб, датчика, діода, датчик, спосіб, дію, іч-діапазону, пристрій, містить, роботи, себе
Формула / Реферат:
1. Пристрій світловипромінювального діода (СВД), що містить СВД (30) ІЧ-діапазону, який випускає позитивну люмінесценцію при напрузі прямого зміщення і випускає негативну люмінесценцію при напрузі зворотного зміщення,засіб збудження для подачі напруг прямого і зворотного зміщення, що чергуються, на СВД,який відрізняється тим, що рівні напруг прямого (+ν1) і зворотного (-ν2) зміщень, що подаються засобом збудження, встановлюють так,...
Попередній патент: Спосіб калібрування двох взаємодіючих один з одним робочих валків в прокатній кліті
Наступний патент: Безоболонкова групова упаковка (варіанти) та спосіб виробництва безоболонкової групової упаковки (варіанти)
Випадковий патент: Стенд для випробування транспортних засобів з відтворенням профілю дорожнього полотна